
¿Qué es el Harness Engineering?
Te explico el Harness Engineering, la disciplina para diseñar entornos deterministas que transforman chatbots genéricos en agentes de desarrollo fiables y seguros.

A final de 2025 escribí un post reflexionando sobre los avances que habíamos vivido durante el pasado año donde criticaba bastante los agentes de IA.
Nos han vendido que los agentes de programación iban a solucionar todos nuestros problemas de desarrollo, pero la realidad no siempre es así. A veces los modelos hacen cosas totalmente increíbles pero otras veces fallan estrepitosamente en lo más simple.
La mayoría de gente en sector comete el error de pensar que la solución pasa por esperar a que salga la próxima versión de GPT o de Claude, confiando en que un modelo más grande y con más parámetros será mágicamente más inteligente. La verdad es que gran parte de las mejoras reales que estamos viendo hoy en día en el ecosistema del desarrollo no vienen de tener mejores modelos, sino de construir mejores entornos en los que estos modelos operan.
Ya tenemos una máquina capaz de escupir miles de líneas de código, nuestra responsabilidad ahora no es revisar cada línea a mano, sino intentar controlar el entorno.
Precisamente de esa necesidad de control nace una disciplina que está cambiando la forma en la que construimos software asistido: el Harness Engineering. Hoy te voy a enseñar a crear sistemas verdaderamente productivos basados en IA.

TL;DR
El Harness Engineering es la disciplina que se encarga de diseñar y construir el ecosistema tecnológico que rodea a un modelo de inteligencia artificial para convertirlo en un agente autónomo, seguro y fiable.
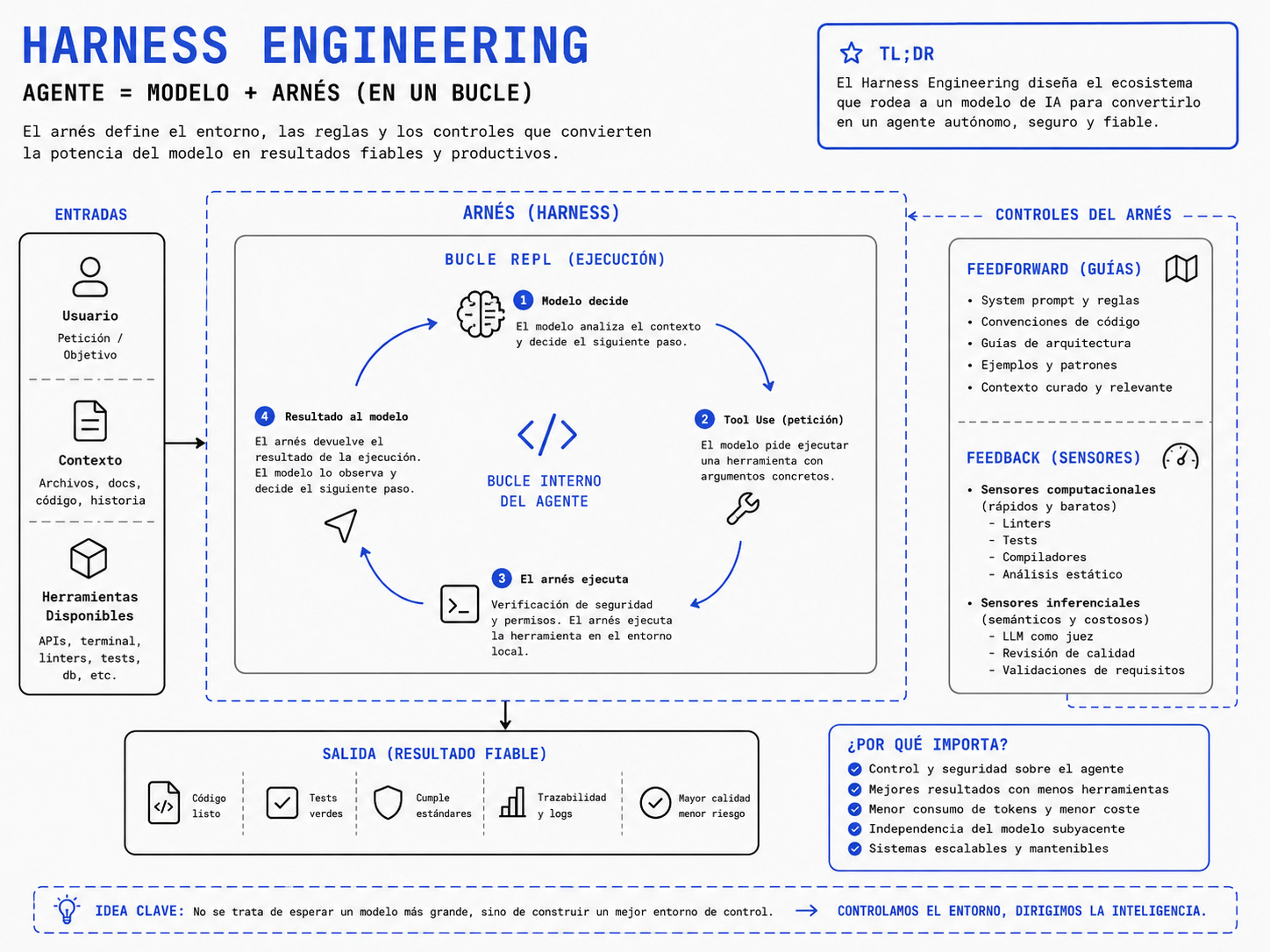
Un agente funcional es la suma del modelo más su arnés de control (Agent = Model + Harness). El arnés orquesta las herramientas, la memoria y el contexto.
La arquitectura se basa en un bucle REPL donde el arnés intercepta las peticiones del modelo, ejecuta las herramientas de forma segura y le devuelve los resultados.
Incorpora guías preventivas (Feedforward) y sensores de corrección (Feedback) mediante evaluaciones computacionales (linters, tests) e inferenciales (IA revisora).
Limitar artificialmente las herramientas y el tamaño del contexto mejora la precisión del modelo y reduce notablemente el gasto en tokens.
Permite automatizar flujos complejos como el Spec Driven Development (SDD) coordinando subagentes aislados que se comunican mediante memoria externa.
Qué es el Harness Engineering y por qué es importante
Imagina un modelo, puedes ser Claude, GPT o cualquier otro que uses a diario, este modelo es nuestro cerebro. Por sí solo, este cerebro es capaz de procesar texto, predecir el siguiente token y razonar sobre conceptos abstractos, pero no tiene forma de tocar el teclado, ni de leer los archivos de tu proyecto y no tiene memoria a largo plazo más allá de la ventana de contexto que le proporciones en ese instante.
El Harness Engineering agrupa todas las prácticas y arquitecturas que consisten en agarrar ese modelo de inteligencia artificial y definirle el entorno que le rodea. El arnés equivale a las riendas que le ponemos al modelo para intentar dirigir su fuerza bruta hacia un objetivo concreto: Agente es igual a Modelo más Arnés en un bucle.
Este entorno o ecosistema que construimos alrededor del modelo se compone de varias piezas fundamentales que tenemos que orquestar:
Por un lado, tenemos la gestión del contexto, que es decidir qué información le enviamos al modelo en cada momento.
Por otro lado, la definición de herramientas (tools) a las que el modelo puede llamar para interactuar con el mundo real, como leer un archivo, ejecutar un comando de terminal o consultar una base de datos.
También necesitamos un sistema de memoria persistente para evitar que la ventana de contexto se inunde con información irrelevante.
Finalmente, también necesitamos mecanismos de validación.
Uno de los mayores beneficios de adoptar el Harness Engineering es que pasas a ser dueño del sistema y si mañana sale un modelo open source hiperbarato que sirve perfectamente para tareas de refactorización rutinaria, simplemente lo enchufas en tu arnés.
Ojo porque mucha gente piensa que construir un buen arnés consiste en darle al modelo acceso absoluto a todo (herramientas, acceso de lectura a todo el disco duro y ventanas de contexto de millones de tokens…) pero es justamente lo contrario. Ha quedado sobradamente demostrado que cuanto más complejo haces el arnés y más herramientas específicas le das al modelo, peor funciona.
El equipo de Vercel documentó hace poco cómo el rendimiento de su agente interno (D0) mejoró cuando eliminaron el 80% de las herramientas que le habían programado inicialmente. Además que reujeron el consumo de tokens en un 37%.
¿Cómo funciona el arnés? Bucles de evaluación y ejecución
En el desarrollo de videojuegos existe el patrón conocido como “Game Loop”, un bucle infinito que en cada iteración o frame lee la entrada del usuario, actualiza el estado físico y lógico del mundo, renderiza los gráficos en la pantalla y vuelve a empezar. Los agentes de inteligencia artificial operan exactamente con el mismo principio estructural.
En la literatura técnica, este patrón suele denominarse bucle REPL, por las siglas en inglés de Read, Eval, Print, Loop.
El bucle principal gestiona la interacción general. Lee lo que el usuario escribe en la interfaz (Read), decide qué hacer con ello (Eval), muestra el resultado en pantalla (Print) y vuelve a esperar (Loop).Pero en el Harness Engineering ocurre dentro de la fase de evaluación. Esa fase no es una simple llamada de red que devuelve un texto, sino que tiene su propio bucle interno, que es donde el agente puede actuar de forma autónoma.
Cuando el usuario introduce una petición, el arnés envía ese mensaje al modelo junto con la lista de herramientas disponibles (la inteligencia artificial no ejecuta ninguna herramienta por sí misma: el modelo no sabe abrir archivos ni compilar código). El modelo simplemente responde con una petición estructurada diciendo: “Oye, necesito que tú, el arnés, ejecutes la herramienta de leer fichero pasándole esta ruta exacta”.
El arnés recibe esta petición (el Tool Use), intercepta el flujo, ejecuta la función localmente en tu máquina para leer el fichero y agarra el contenido resultante. Luego, en la siguiente iteración de ese bucle interno, el arnés le manda al modelo un nuevo mensaje diciéndole: “Vale, he ejecutado la herramienta que pediste y aquí tienes el resultado”. El modelo lee la información, razona sobre ella y decide su siguiente paso. Puede pedir ejecutar un comando de bash para compilar, o puede determinar que ya tiene toda la información necesaria y formular la respuesta final para el usuario.
A continuación te muestro un ejemplo en Go donde defino un bloque donde se itera sobre las respuestas del modelo, evaluando el tipo de salida:
for {
// 1. Enviamos el contexto y los mensajes actuales al modelo
respuestas := proveedor.EnviarMensaje(contexto, mensajes)
todasHerramientasEjecutadas := true
for _, resp := range respuestas {
if resp.EsLlamadaHerramienta() {
// 2. El modelo pide usar una herramienta. El arnés toma el control.
todasHerramientasEjecutadas = false
// 3. Verificación de seguridad y permisos (Harness Engineering)
if !pedirAprobacionHumana(resp.NombreHerramienta, resp.Argumentos) {
agregarMensajeError(mensajes, "El usuario denegó la ejecución")
continue
}
// 4. Ejecución real en el entorno local
resultado := ejecutarHerramienta(resp.NombreHerramienta, resp.Argumentos)
agregarResultadoHerramienta(mensajes, resp.ID, resultado)
}
}
// 5. Si el modelo no pidió más herramientas, terminamos el bucle interno
if todasHerramientasEjecutadas {
break
}
}Esta abstracción es el core de cualquier sistema agéntico profesional.
Control: Feedforward y Feedback
Ya tenemos el bucle de ejecución pero… ¿Cómo comprobamos y nos aseguramos que ese código cumple con nuestros estándares? Sabemos que los LLMs son no deterministas, que carecen de contexto organizativo y que, en el fondo, no entienden semánticamente el código ya que operan prediciendo tokens de forma probabilística.
Para solucionar esto, un arnés bien diseñado incorpora dos tipos de controles complementarios: mecanismos de Feedforward (Guías) y mecanismos de Feedback (Sensores).
Los controles de Feedforward, o guías, actúan antes de que el agente empiece a escribir. Su objetivo es anticipar el comportamiento de la inteligencia artificial y dirigirla para aumentar la probabilidad de que acierte al primer intento. Esto incluye desde el System Prompt general, hasta inyectar de forma dinámica las convenciones de código de tu proyecto, guías de estilo o documentos de arquitectura directamente en la ventana de contexto antes de formular la petición.
Los sensores son programas ejecutados por la CPU como los tests unitarios, los linters, los analizadores estáticos de código o el propio compilador. El arnés pilla la salida de un linter que ha fallado y se la devuelve automáticamente al agente de IA con un mensaje como: “Tu código ha generado este error de compilación en la línea 45. Arréglalo”.Los controles de Feedback, o sensores, actúan después de que el agente haya escrito el código, permite corregirse sin intervención humana. Es imposible garantizar que un modelo probabilístico acierte siempre a la primera.
Los sensores inferenciales se apoyan en otros modelos de IA (o en el mismo) para realizar juicios semánticos que herramientas programáticas no pueden evaluar. Este es el famoso patrón de “LLM como Juez”. Obviamente, estos controles inferenciales consumen GPU, tardan más y cuestan dinero, por lo que un buen Harness Engineering consiste en orquestarlos estratégicamente, manteniendo la calidad en las fases tempranas del ciclo de vida del desarrollo.
¿Cómo diseñar un buen arnés?
Tenemos tres grandes áreas de regulación que deberíamos considerar al crear un arnés (en el contexto de la programación y el desarrollo de software)
La primera es el arnés de mantenibilidad (Maintainability harness): Su foco es la calidad interna del código. Aquí es donde integramos nuestras herramientas tradicionales. Son controles baratos y rápidos que el arnés puede invocar en cada iteración del bucle interno. Los LLMs pueden complementar esto identificando duplicidad semántica (código que hace lo mismo pero está escrito distinto), aunque su uso debe ser más esporádico por el coste de inferencia.
La segunda categoría es el arnés de idoneidad arquitectónica (Architecture fitness harness): Ya no buscamos solo que el código esté limpio, sino que respete las características de la arquitectura de la aplicación. Podemos inyectar guías que dicten estándares de observabilidad y logging, y utilizar sensores como tests estructurales para asegurarnos de que el agente no ha roto los límites entre módulos de dominio al intentar solucionar rápido un bug.
La tercera, y más compleja, es el arnés de comportamiento (Behaviour harness): ¿Cómo validamos que la aplicación hace funcionalmente lo que se supone que debe hacer? La solución aquí sigue requiriendo una fuerte especificación humana previa.
Ojo, hay que tener en cuenta que no todos los proyectos son igual de propensos a ser domados por un arnés y habrá casos donde funcione mejor que en otros.
Y, evidentemente, estas tres áreas están centradas en el desarrollo de software pero hay muchos usos y aplicaciones del uso de agentes fuera de la programación que necesitarían un arnés completamente diferente.
Referencias técnicas
Harness engineering for coding agent users - Artículo fundacional de Birgitta Böckeler en el blog de Martin Fowler sobre la aplicación de conceptos de cibernética y teoría de control a los agentes de programación.
¿Qué es esto del Harness Engineering? - Análisis conceptual en vídeo sobre el rol del ecosistema en el rendimiento de los modelos, el problema de la hiperespecialización de herramientas y el uso de memoria externa frente a ventanas de contexto.
Esto es lo que Aprendí Adaptando Claude Code para SDD - Guía práctica de orquestación multiagente aplicando Spec Driven Development (SDD), curación de contexto y separación de responsabilidades estructurales.
Model Context Protocol (MCP) - Estándar abierto para conectar de forma unificada modelos fundacionales con herramientas de datos y sistemas en entornos de desarrollo.
Anthropic API Documentation - Tool Use - Referencia técnica oficial sobre la estructuración de bucles de evaluación en modelos de la familia Claude.